前回AT Protocolでよく出てくるCBOR・CID・DAG-CBORについて調査・まとめました。これらがAT Protocol中で主に出てくるのはRepositoryに関する仕様1の部分です。今回はRepositoryとは何か、Repositoryに使われるMerkle Search Treeとは何か、どうやってデータが管理されるのか調べたことをまとめました。
Repositoryとは
概要
アカウントごとのデータの集まりです。PDSがRepositoryを管理しています。Repositoryの中のデータはCollectionというグループでまとめられています。データの自身はRecordと呼ばれています。投稿テキスト・画像・動画などといったデータの種類は限定されていません。数量関係としては、
- アカウントとRepositoryは1対1
- RepositoryとCollectionは1対多
- CollectionとRecordは1対多
となります。
この構造ゆえ、Repository・Collection・RecordのIDが分かれば、データを一意に指定できます。これを簡潔に表現するフォーマットがAT URIです。AT URIは
at://foo.com/com.example.foo/123
のような形式です。foo.comという人のcom.example.fooというCollectionにある123というIDのデータを指し示しています。正式な定義はドキュメントを参照してください。公式ドキュメントではCollection名はそれを生成するLexicon名に一致させる例が多く見られるので、そういう使い方を想定してそうです。
あるPDSが管理しているRepository中のRecordを取得したい場合、Repository, Collection, Resourceのキー2を引数とするcom.atproto.repo.getRecord Lexiconを叩きます。取得以外にもCRUDはcom.atproto.repo.*のLexiconで定義されています。RecordはデータのCIDなので、データ本体を得る方法は別途必要です(RepositoryのdidとデータのCIDを引数とするcom.atproto.sync.getBlobを叩けば良い?)。
PDSはRepositoryのデータをMerkle Search Treeで管理しなければならない
ここまでの説明では、RepositoryはAT URIをキーとしてデータを返す単なるKVSとして振る舞えば良いように聞こえます。しかし、単なるKVSと異なるのは、Repository構造をMerkle Search Tree(MST)3で管理しなければならない45ということです。次の節でMSTとはどんなものかを述べます。
Merkle Search Tree
概要
Merkle Search TreeはB木に類した木構造です。ノード間のリンクを、参照先のノードのハッシュ値で表現していることが特徴です。元々はネットワークのノードが増えたり減ったりする環境で分散KVSなどを効率的に実装するためのデータ構造の一種として提案されました。値の取得、レンジスキャン、追加する値が追加順序に対して単調増加である場合の追加操作を効率的に行なえます。
ノード間のリンクがハッシュ値を利用しているので、データの変更が起きるとリンクの再計算が発生し、ルートハッシュまで波及します6。暗号学的ハッシュ関数の性質から、ルートハッシュを指定することは、保存されているデータを指定することと大体等価です7。AT Protocolでは、ユーザーがデータを作ったとき、PDSはユーザーの署名鍵でRepositoryのルートハッシュを含むデータであるCommitを作り、Commitにデジタル署名を行います。Commitに対する改ざんは署名と齟齬が出るのでわかりますし、Repositoryに対する改ざんは、ルートハッシュを計算したときCommit内容と齟齬が出るのでわかります。
Repositoryへの改ざんを第三者が検知するためにCommitが必要なので、PDSはCommitを提示できる必要があります。Repositoryをエクスポートする際に使用されるCAR v1フォーマットはCommitオブジェクトを含むことが規定されています。com.atproto.sync.getCheckout LexiconはRepositoryをエクスポートするAPIを規定しています。このAPIを叩けばCommitがついてくるので、改ざんを検証できます。
以下はMSTの技術的詳細です。正直AT Protocolが本当に普及するならMSTをきれいに隠蔽し切るライブラリなりデータベースが出ているはずなので知っておく必要はあまり無いです。
MSTの構造
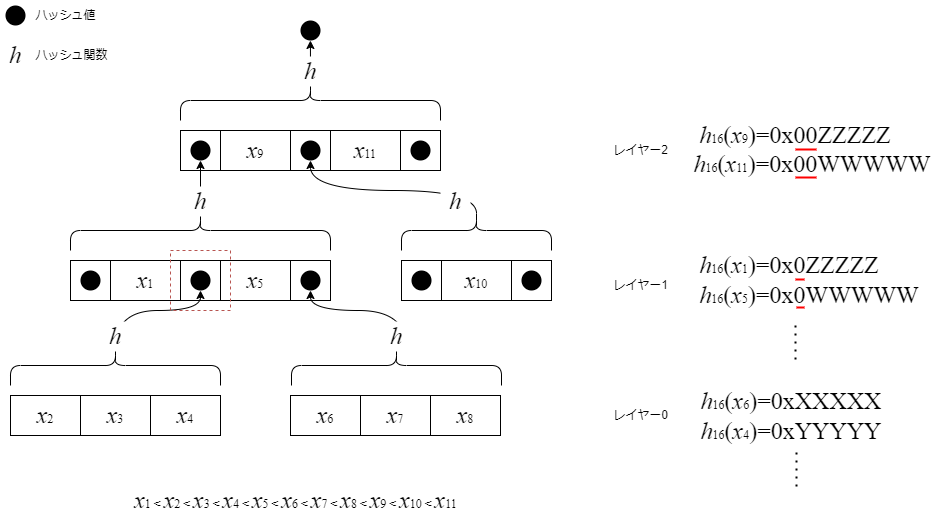
MSTは木構造の各深さのことを「レイヤー」と呼んでいます。同じレイヤー内のノードは左から右にソートされています。また、ノード間は下層レイヤーのノードにリンクが貼られています。リンク先のノードの値の範囲は、リンクの位置で決まっています。例えば、図の赤い点線で示したリンクは、x1とx5の間に描かれている通り、x1<x<x5となるデータが入っているノードを指し示しています。
ある値xをMSTに追加する際は次のような手順を踏みます。
- xが最終的に入るレイヤーを計算します。まず、xのハッシュ値h(x)を計算し、基数Bで表記します。図では16進数で表記しています。表記されたハッシュ値の頭から0の個数を数えます。ここではl個であるとします。xはレイヤーlに入ることになります。
- xがどのサブツリーに入るかを上位レイヤーから決めていきます。ノード内はソートされているので、ノード内のエントリーをランダムアクセス可能な構造で保持しているなら、二分探索でxが入る位置を決められます。今見ているレイヤーがlではない場合、リンクを辿って次のレイヤーに降ります。降りた先のレイヤーで同じ手順を繰り返します。今見ているレイヤーがlである場合、xをその位置に挿入します。
- xを挿入したことで、lより下層のノードに分割が必要になる可能性があります。例えば、上図でレイヤー1にx3<x<x4となるxを挿入するとします。この場合、レイヤー0のx2,x3,x4のノードは、x2,x3のノードとx4のノードに分割されることになります。
- xを追加した結果リンクのハッシュ値が変化するので、下層から順番に、ハッシュ値を再計算します。
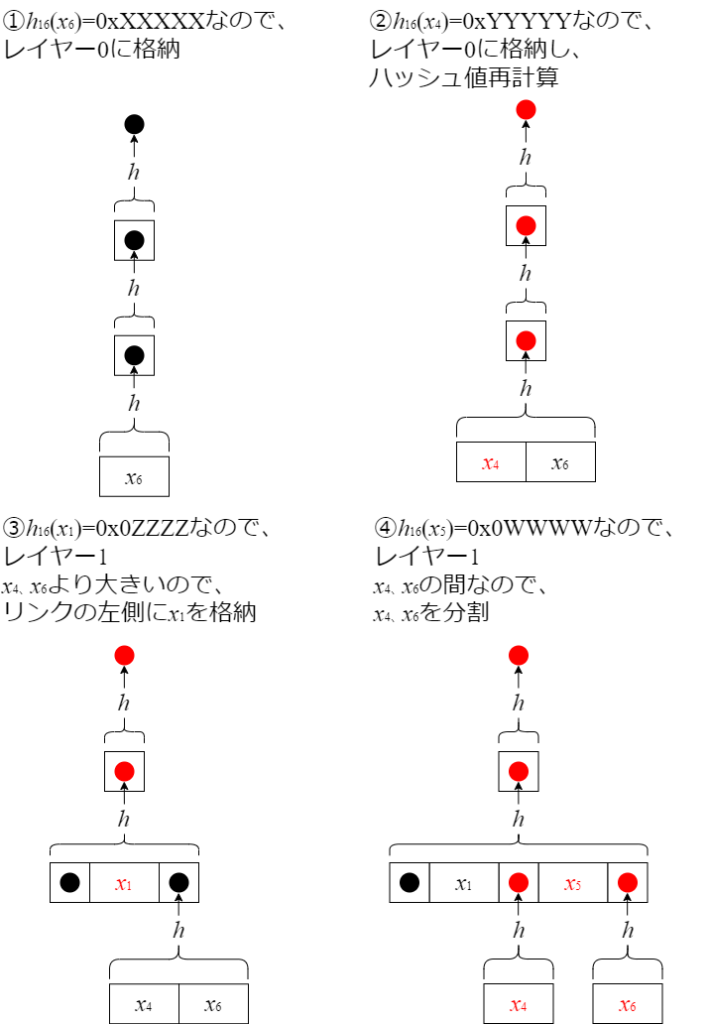
値が追加順序に対して単調増加なら、データ挿入は必ずノード末尾への追加となるので、効率的に行えます。
CRDTとしてのMST
分散環境で一つのデータ構造を保持したいことがあります。例えば、ワーカーが複数存在するWebサービスでアクセス数を計算したい場合を考えます。分散しているメリットを維持するため、アクセス数をカウントする単一の何かを用意するのではなく、個々のワーカーが会話することで全体のアクセス数が求まるようなアルゴリズムが望ましいです。また、すぐ分からなくても、いずれ求まればいいとします。CRDT (Conflict-free Replicated Data Type)はそういう問題に役立つデータ構造です。CRDTはワーカーごとに保持したいデータ構造のレプリカを持っています。各時点ではレプリカの状態はワーカーごとにばらつくことが許容されますが、ワーカー間の会話で、状態をマージしていき、十分長い時間待てば全ワーカーが同じ状態に収束します。状態がマージできるために、データ構造に対して行える操作が、可換な操作に限定されます。アクセス数カウンタの例では、インクリメントという可換操作のみなので、CRDTを実装できます。また、要素追加しかできない集合もCRDTにできます。
MSTはCRDTなマップを実装するのに使えます。MSTにはマップのキーを入れ、マップの値は集合型の変数だとします。集合型の変数には要素追加だけができるとします。マップのマージをしたい場合、キーと値をマージすることで、マップの状態が1つに収束します。
MSTが嬉しい点は、MST同士の比較が効率的であることです。というのは、ルートノードから順に各リンクのハッシュ値を比較し、一致していればそのリンクが指す下層ノードを見る必要が無いからです。差異があるノードだけをやり取りでき、マージのために必要なバンド幅と時間が小さくて済みます。
AT ProtocolにおけるMST
AT ProtocolではRepositoryのパスをキーとし、MSTに保持します。キーの形式は<コレクション名>/<Recordのキー>をUTF-8でエンコードした値です。ハッシュ値の計算に使用するのはSHA-256であり、レイヤー8計算に使用する基数はB=4です。例えば、
app.bsky.feed.post/454397e440ec
というパスをUTF-8でエンコードし、SHA256を計算して2進数で表現すると、
0000000001101101001111011110001110010110001101010011100011101010110101111000000001111101001001100011011000001000010011111111110001001000011000110000101110110101101110000001100010101100101110001000000011111100110110100110010111100000111110101100010100000100
です。頭から「00」が4回続いているので、レイヤー4に入ります。
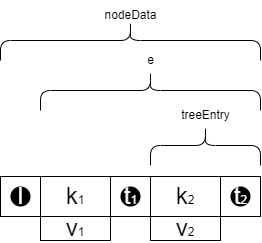
公式実装では、MSTの各ノードは下のような構造を持っています。
const treeEntry = z.object({
p: z.number(), // このtreeEntryの左隣のキーとプリフィックスが一致する文字数
k: common.bytes, // 残りのキー
v: common.cid, // このキーに紐づくデータのCID
t: subTreePointer, // 右側のリンク(CID)
})
const nodeData = z.object({
l: subTreePointer, // このノードの一番左のリンク(CID)
e: z.array(treeEntry), // 各treeEntry
})各ノードは「一番左のリンク+ノードデータの配列」となっていて、ノードデータはキーと右側のリンクを持っています。また、各ノードがキー全体をそのまま持っていると冗長になる9ので、左のtreeEntryと重複する文字数をpに保持しておいて、差異がある部分だけkに持っておくようにしています。treeEntryそのものはデータのCIDのみを持っており、データ本体(blob)は別の場所に置かれています。
図示すると下のとおりです。
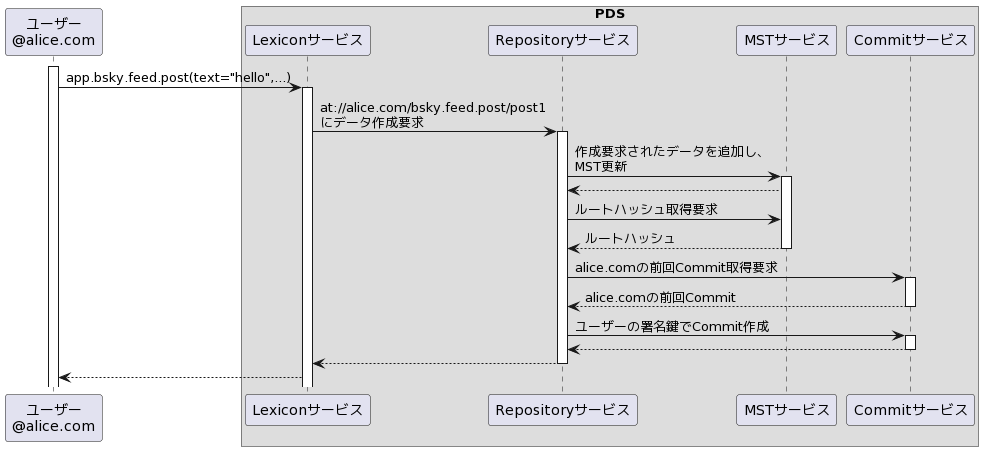
データ作成の流れ
以下は公式実装ではなく、Lexicon/Repository/MST/Commitがどう結びついているかを描いたものです。
なぜプロトコルがサーバー内のデータの保存の仕方を指定するのか(考察)
AT Protocolの使命の一つはアカウントの可搬性を実現することです。あるPDSが潰れたとき、あるいはPDSを変えたいとき、ユーザーは自分が作ってきたデータを持ち運びたいはずです。あるいは最低でも、昔そういうデータを作ったという記録だけでも残したいはずです。
例えば、次のような例を考えます。ユーザーAがどこかのPDSで発言したとします。at://user-A.com/app.bsky.feed.post/1がユーザーAの元の発言とします。ここで、ユーザーAが使っているPDSがサービス終了したとします。Repositoryの可搬性がないと、Aが過去にat://user-A.com/app.bsky.feed.post/1という発言をしていた記録はどこにもなくなります。これだとAがその後別PDSを使い始めても、実質アカウントを別PDSで作り直したのと同じです。
AT Protocolでは、Repositoryを管理するデータ構造(MST)、そのデータ構造をエクスポート・インポートするためのLexicon(com.atproto.sync.getRepo)、エクスポートされたデータのファイル形式(CAR)を定めています。これらを共通規格にすることで、ユーザーが何のデータを作ってきたかという記録を持ち運べるようになります。先程の例では発言そのものが失われても、発言をしたという記録は残り、アカウントの連続性が保たれます。なお、データそのものをCARに含める議論もされているようです。
まとめ
- Repositoryはアカウントごとのデータの集まりで、Repository→Collection→Recordという階層を持つ
- データはat://<Repository(アカウントのdid)>/<Collection>/<Record>というURIで一意に指定できる
- RepositoryのデータはMerkle Search Tree (MST)で管理される
- MSTは値取得・レンジスキャン・単調増加するキーの追加を効率的に行なえる。また、分散KVSなどを実装するのに使える。
- MSTはノードを指し示すのにハッシュ値を利用している。データの変更はルートハッシュに波及する。
- Repositoryへの変更のたびに、Commitオブジェクトを作成する。Commitオブジェクトはその時のMSTルートハッシュと、ユーザーの署名鍵によるデジタル署名を含んでいる。
話が込み入っていて、Repository周りはきれいに隠蔽するライブラリなりデータベースが必須だと思いました。
- 2023年7月現在
- OptionalでRecordのバージョンを指定するCID
- Alex Auvolat, François Taïani. Merkle Search Trees: Efficient State-Based CRDTs in Open Networks. SRDS 2019 – 38th IEEE International Symposium on Reliable Distributed Systems, Oct 2019, Lyon, France. pp.1-10, ff10.1109/SRDS.2019.00032
- 今のドキュメントではMUSTやSHOULDの厳密な使い分けがされていないので「しなければならない」は推測です
- なんで被引用数22回の新規手法を選んだんだろう…
- というのはより歴史の深いMerkle Treeも持っている性質です。Merkle Treeにしないのは分散環境を想定しているということでしょう。
- ハッシュ値が衝突するデータを見つけるのが難しい、という点で
- AT Protocolドキュメント中の用語ではdepth
- 1個目のパスがbsky/posts/abcdefgで、2個目がbsky/posts/abcdehiなら、k2はp=16、k=hi となります

コメント